Basics#
[ ]:
import sys
sys.path.append('..')
import os
n_cores = int(8)
os.environ["OMP_NUM_THREADS"] = f"{n_cores}"
os.environ["OPENBLAS_NUM_THREADS"] = f"{n_cores}"
os.environ["MKL_NUM_THREADS"] = f"{n_cores}"
os.environ["VECLIB_MAXIMUM_THREADS"] = f"{n_cores}"
os.environ["NUMEXPR_NUM_THREADS"] = f"{n_cores}"
os.environ["NUMBA_CACHE_DIR"]='/tmp/numba_cache'
import numpy as np
from sklearn_ensemble_cv import reset_random_seeds
import matplotlib.pyplot as plt
reset_random_seeds(0)
We make up some fake data for illustration.
[2]:
from sklearn.datasets import make_regression
from sklearn.model_selection import train_test_split
X, y = make_regression(n_samples=300, n_features=200,
n_informative=5, n_targets=1,
random_state=0, shuffle=False)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=42)
The Ensemble class#
For users who want to have more control of the ensemble predictor, this section introduces lower-level class and object that we use to implement the cross-validation methods. For users who just want to use easy interface functions, you can safely skip this section.
We provide Ensemble a class for ensemble predictor, whose base class is sklearn.ensemble.BaggingRegressor. This means that the usage of Ensemble is basically the same as the latter, except the new class includes several new member functions that we will illustrate below.
Initialize an object#
The initialization of Ensemble class is the same as sklearn.ensemble.BaggingRegressor, where
The base estimator object, whose hyperparameter
kwargs_regris specified when it is initialized. In the following example, we use decision tree as the base estimator.The hyperparameters for building an ensemble, such as
n_estimators,max_samples,max_features, and etc.
[3]:
from sklearn.tree import DecisionTreeRegressor
from sklearn_ensemble_cv import Ensemble
kwargs_regr = {'max_depth': 7}
kwargs_ensemble = {'max_samples': 0.8}
regr = Ensemble(estimator=DecisionTreeRegressor(**kwargs_regr), n_estimators=100, **kwargs_ensemble)
After the ensemble object regr is initialized, we can fit the data and get the prediction:
[4]:
regr.fit(X_train, y_train)
regr.predict(X_test)
[4]:
array([ 1.55258626e+02, -3.05994688e+01, -3.08717707e+01, 4.59185397e+01,
-1.31673233e+02, -1.53618401e+01, -7.58969354e+00, 5.55612647e+01,
-2.49650470e+01, -8.64505794e+01, 5.30470606e+00, -1.65026872e+00,
-1.68937357e+02, -3.64697321e+01, 1.09240808e+02, -3.61555106e+01,
1.70139644e+02, 5.07345762e+01, -4.57768586e+01, -6.36637535e+01,
1.98450292e+01, -5.88202620e+01, 1.32874009e+02, -1.63522372e+02,
-1.28692376e+02, -5.88109839e+01, 5.19530446e+01, 1.42758358e+01,
3.30152254e+01, -4.05912157e+01, -5.82506190e+01, -1.24873797e+01,
-1.75895663e+02, 9.75114150e+01, 8.74697325e+01, 5.13658483e+01,
-1.27636452e+02, -3.21727865e+01, 1.46534143e+02, 1.51187165e+02,
-1.23416630e+02, -1.35952080e+01, -4.85622867e+01, -4.10217919e+01,
-1.45807260e+02, 1.25982796e+02, -6.55997321e+00, 6.87142111e+01,
6.01303870e+01, 1.59088989e+02, -6.05490517e+01, -1.89612897e+01,
-7.83841416e+01, -1.98655475e+01, -2.07795599e+00, 9.06000291e+01,
1.56802764e+02, -4.79037791e+00, 1.63049008e+02, -1.95082888e+02,
1.98327834e+02, 3.22210898e+01, 1.13020203e+01, -1.23629912e-01,
8.36659821e+01, 9.17160516e+01, -3.25095987e+01, -1.04825033e+01,
-3.54178679e+01, 6.38551655e+01, 5.40532228e+01, 2.02374291e+01,
-7.40274616e+01, 1.32490998e+01, -4.09384762e+01, 1.55996605e+02,
-3.97031336e+01, -8.84950965e+01, -9.79128997e+01, -1.20241144e+02,
1.18386965e+02, 1.50236875e+02, -2.09861849e+02, -5.49399208e+01,
-7.82686509e+01, -1.02451741e+02, -4.25753316e+01, -1.32619362e+02,
-4.33093105e+01, -4.66723558e+01, 1.65050613e+02, -8.70596762e+01,
2.30991348e+00, 4.20654775e+01, -1.53247921e+02, -1.57785888e+02,
1.77328813e+02, 1.17652845e+01, 1.97861320e+01, 7.12165424e+01,
1.01746011e+02, -2.54085468e+01, 7.05913116e+01, 1.14362733e+01,
-1.95851324e+02, 2.76538247e+01, -7.24716237e+01, -7.70112213e+01,
-1.34312439e+02, -1.39850788e+01, -9.38177348e+01, -1.99134689e+01,
-2.92722574e+01, -1.35896063e+02, 7.67209370e+01, 2.95641797e+01,
-5.21496990e-01, -1.77364655e+02, -1.27670449e+02, -1.36452786e+02,
1.19583568e+01, -1.36222497e+02, -8.87966870e+01, 5.22172522e+01,
-1.30654048e+02, 3.00035105e+01, -2.06507219e+01, 4.73462564e+01,
-1.50207963e+01, 1.87159008e+01, 4.70190920e+01, -1.53884335e+02,
3.26657747e+01, 1.06385038e+01, 1.39514153e+02, -1.14965025e+02,
1.66933169e+02, 1.16198895e+01, -3.71584600e+01, -1.38855162e+01,
-1.05179205e+02, 3.49003320e+01, -1.11235050e+02, -2.98637151e+01,
1.74088266e+02, 1.94641882e+02, -6.04350092e+01, -4.83500392e+00,
-1.43971902e+02, 1.59488916e+02])
Prediction of individual estimators#
We provide a new function predict_individual to obtain prediction values from all estimators in the ensemble. Since we have \(n=150\) observations and \(M=100\) estimators, the resulting prediction would be of shape \((n,M)=(150,100)\).
[5]:
Y_train_hat = regr.predict_individual(X_train)
Y_train_hat.shape
[5]:
(150, 100)
Compute ECV estimate of the prediction risk#
Below, we use function compute_ecv_estimate to estimate the prediction risk for various ensemble size \(M=1,\ldots,100\), only using the first \(M_0=30\) trees.
[6]:
df_est = regr.compute_ecv_estimate(X_train, y_train, M0=30, return_df=True)
df_est
[6]:
| M | estimate | |
|---|---|---|
| 0 | 1 | 16545.259516 |
| 1 | 2 | 11039.442773 |
| 2 | 3 | 9204.170525 |
| 3 | 4 | 8286.534401 |
| 4 | 5 | 7735.952727 |
| ... | ... | ... |
| 95 | 96 | 5648.330545 |
| 96 | 97 | 5647.148024 |
| 97 | 98 | 5645.989637 |
| 98 | 99 | 5644.854651 |
| 99 | 100 | 5643.742364 |
100 rows × 2 columns
We can also compute the test error on the test set using function compute_risk.
[7]:
df_risk = regr.compute_risk(X_test, y_test, return_df=True)
df_risk
[7]:
| M | risk | |
|---|---|---|
| 0 | 1 | 15740.161966 |
| 1 | 2 | 10714.265053 |
| 2 | 3 | 9699.114654 |
| 3 | 4 | 8950.480255 |
| 4 | 5 | 8268.258825 |
| ... | ... | ... |
| 95 | 96 | 5875.571676 |
| 96 | 97 | 5881.180617 |
| 97 | 98 | 5881.094324 |
| 98 | 99 | 5882.142533 |
| 99 | 100 | 5880.883707 |
100 rows × 2 columns
If we plot both the risk estimate and the actual test error, we see a close match.
[8]:
plt.plot(df_est['M'], df_est['estimate'], label='estimate')
plt.plot(df_risk['M'], df_risk['risk'], label='risk')
plt.legend()
plt.show()
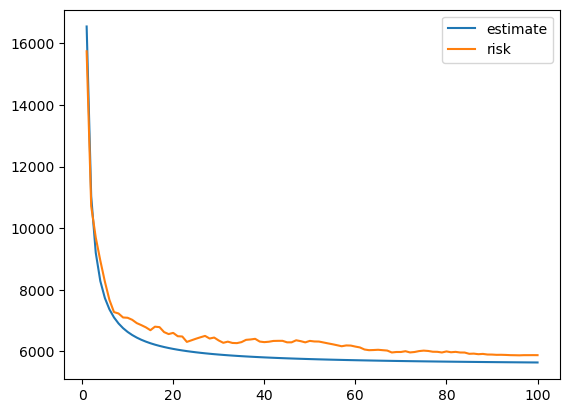
Above we show two basic functions and their usage. One utility of ECV method is that we can also get a risk estimate beyond \(M=100\), which gives us a sense how much improvement one can get if we further increase the ensemble size.
[9]:
df_est = regr.compute_ecv_estimate(X_train, y_train, M_test=1000, M0=30, return_df=True)
df_est
[9]:
| M | estimate | |
|---|---|---|
| 0 | 1 | 16545.259516 |
| 1 | 2 | 11039.442773 |
| 2 | 3 | 9204.170525 |
| 3 | 4 | 8286.534401 |
| 4 | 5 | 7735.952727 |
| ... | ... | ... |
| 995 | 996 | 5544.681887 |
| 996 | 997 | 5544.670797 |
| 997 | 998 | 5544.659731 |
| 998 | 999 | 5544.648686 |
| 999 | 1000 | 5544.637663 |
1000 rows × 2 columns
ECV estimate for one configuration of ensemble predictors#
The function comp_empirical_ecv provides an easy way to fit and get risk estimate from ECV. Similar to the previous section, one need to provide
Data:
X_train, y_train.A regressor class and the parameters to initialize it:
DecisionTreeRegressor, kwargs_regr=kwargs_regr.The parameters for building the ensemble (with
Mdenotingn_estimators):kwargs_ensemble=kwargs_ensemble, M=50.Extra optional parameters for ECV.
The function returns two objects:
An ensemble predictor (an object of
Ensemble)A np.array or pd.DataFrame object, containing the risk estimates given by ECV.
[10]:
from sklearn_ensemble_cv import comp_empirical_ecv
kwargs_regr = {'max_depth': 7}
kwargs_ensemble = {'max_samples': 0.8}
regr, risk_ecv = comp_empirical_ecv(X_train, y_train, DecisionTreeRegressor, kwargs_regr=kwargs_regr,
kwargs_ensemble=kwargs_ensemble, M=50)
One can also pass kwargs X_val=X_test, Y_val=y_test to get the actual test errors.
ECV for tuning hyperparameters#
For tuning hyperparameters, such as max_samples and max_features for the ensemble predictors, and max_depth and min_samples_leaf for all base predictors, we can make two grids of these two types of tuning hyperparameters respectively.
We recommend using np.array for each parameter, and make sure to use the correct dtypes that sklearn accept. If one want to set some hyperparameter to a fix value, simply provide it in the grid as either a scalar or a list/array with length one.
[11]:
from sklearn_ensemble_cv import ECV
# Hyperparameters for the base regressor
grid_regr = {
'max_depth':np.array([6,7], dtype=int),
}
# Hyperparameters for the ensemble
grid_ensemble = {
'max_features':np.array([0.9,1.]),
'max_samples':np.array([0.6,0.7]),
}
res_ecv, info_ecv = ECV(
X_train, y_train, DecisionTreeRegressor, grid_regr, grid_ensemble,
X_test=X_test, Y_test=y_test,
M=50, M0=25, return_df=True
)
[12]:
res_ecv
[12]:
| max_depth | max_features | max_samples | risk_val-1 | risk_val-2 | risk_val-3 | risk_val-4 | risk_val-5 | risk_val-6 | risk_val-7 | ... | risk_test-41 | risk_test-42 | risk_test-43 | risk_test-44 | risk_test-45 | risk_test-46 | risk_test-47 | risk_test-48 | risk_test-49 | risk_test-50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 0.9 | 0.6 | 38766.092506 | 27130.954106 | 23252.574639 | 21313.384906 | 20149.871066 | 19374.195173 | 18820.140963 | ... | 20400.955895 | 20473.966021 | 20516.852272 | 20564.383652 | 20568.895484 | 20548.386056 | 20461.303545 | 20416.347005 | 20338.212307 | 20330.910766 |
| 1 | 6 | 0.9 | 0.7 | 38545.982251 | 27685.957696 | 24065.949511 | 22255.945418 | 21169.942963 | 20445.941326 | 19928.797299 | ... | 20318.713727 | 20440.861775 | 20411.974909 | 20442.347693 | 20448.785333 | 20427.551253 | 20274.764944 | 20176.546011 | 20022.390675 | 19990.362412 |
| 2 | 6 | 1.0 | 0.6 | 17906.660078 | 12049.342285 | 10096.903020 | 9120.683388 | 8534.951609 | 8144.463756 | 7865.543861 | ... | 6654.190713 | 6625.412906 | 6633.298597 | 6636.450315 | 6624.454695 | 6607.368851 | 6589.791652 | 6561.776567 | 6521.960893 | 6508.579021 |
| 3 | 6 | 1.0 | 0.7 | 17768.782775 | 11762.499915 | 9760.405628 | 8759.358485 | 8158.730199 | 7758.311342 | 7472.297872 | ... | 6746.849503 | 6751.183654 | 6724.878113 | 6697.482424 | 6684.798082 | 6688.219217 | 6711.816709 | 6738.490807 | 6784.242634 | 6787.740169 |
| 4 | 7 | 0.9 | 0.6 | 39335.856987 | 27626.621767 | 23723.543361 | 21772.004157 | 20601.080636 | 19820.464954 | 19262.882325 | ... | 20528.039838 | 20568.708815 | 20605.307823 | 20632.828610 | 20630.262989 | 20585.590830 | 20492.588286 | 20430.862922 | 20334.595979 | 20313.901931 |
| 5 | 7 | 0.9 | 0.7 | 38394.185018 | 27696.607514 | 24130.748346 | 22347.818762 | 21278.061012 | 20564.889178 | 20055.480726 | ... | 20139.080395 | 20199.000964 | 20148.318891 | 20165.814865 | 20171.442945 | 20141.663703 | 20001.089341 | 19908.831302 | 19773.342778 | 19734.671204 |
| 6 | 7 | 1.0 | 0.6 | 17900.269535 | 12129.858040 | 10206.387541 | 9244.652292 | 8667.611142 | 8282.917042 | 8008.135543 | ... | 6612.991848 | 6557.674233 | 6552.774417 | 6545.191061 | 6527.502604 | 6520.365373 | 6502.011696 | 6480.311467 | 6454.951325 | 6438.797136 |
| 7 | 7 | 1.0 | 0.7 | 17691.335912 | 11718.687022 | 9727.804059 | 8732.362577 | 8135.097688 | 7736.921095 | 7452.509244 | ... | 6403.204525 | 6420.395641 | 6404.231034 | 6377.207600 | 6366.631308 | 6361.084780 | 6399.403605 | 6430.945089 | 6481.865780 | 6489.090550 |
8 rows × 104 columns
[13]:
info_ecv
[13]:
{'best_params_regr': {'max_depth': 7},
'best_params_ensemble': {'random_state': 0,
'n_estimators': 50,
'max_features': 1.0,
'max_samples': 0.7},
'best_n_estimators': 50,
'best_params_index': 7,
'best_score': 5984.944087677355,
'delta': 0.0,
'M_max': inf,
'best_n_estimators_extrapolate': inf,
'best_score_extrapolate': 5746.038132076163}
[14]:
res_ecv.iloc[info_ecv['best_params_index']]['risk_test-{}'.format(info_ecv['best_n_estimators'])]
[14]:
6489.090550260457
SplitCV#
[15]:
from sklearn_ensemble_cv import splitCV
res_splitcv, info_splitcv = splitCV(
X_train, y_train, DecisionTreeRegressor, grid_regr, grid_ensemble,
M=50, return_df=True, X_test=X_test, Y_test=y_test,
random_state=0, test_size=0.25,
)
[16]:
res_splitcv
[16]:
| max_depth | max_features | max_samples | risk_val-1 | risk_val-2 | risk_val-3 | risk_val-4 | risk_val-5 | risk_val-6 | risk_val-7 | ... | risk_test-41 | risk_test-42 | risk_test-43 | risk_test-44 | risk_test-45 | risk_test-46 | risk_test-47 | risk_test-48 | risk_test-49 | risk_test-50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 0.9 | 0.6 | 34236.829374 | 24572.859001 | 24089.331547 | 20126.642795 | 19197.691635 | 19186.518328 | 18221.490588 | ... | 20701.738963 | 20777.233024 | 20772.732219 | 20796.082041 | 20791.271087 | 20727.242272 | 20616.403023 | 20523.375255 | 20380.819539 | 20347.093017 |
| 1 | 6 | 0.9 | 0.7 | 34580.811141 | 25643.115466 | 23029.787721 | 19895.601540 | 17891.692078 | 17474.479137 | 17490.012418 | ... | 20223.272572 | 20324.397763 | 20276.894389 | 20290.823162 | 20318.546308 | 20256.874357 | 20170.205996 | 20082.758205 | 19945.267248 | 19917.513965 |
| 2 | 6 | 1.0 | 0.6 | 16965.823750 | 10651.257039 | 7820.469737 | 8549.417187 | 7626.003090 | 6258.777113 | 5719.689532 | ... | 7121.881773 | 7203.974379 | 7208.648403 | 7163.960004 | 7128.238064 | 7096.740403 | 7099.966528 | 7109.442178 | 7125.686639 | 7124.766814 |
| 3 | 6 | 1.0 | 0.7 | 16083.117767 | 10094.510250 | 7580.273496 | 7703.161182 | 7472.627416 | 5658.812631 | 5325.656624 | ... | 6768.441759 | 6818.322381 | 6813.679161 | 6806.056024 | 6793.418635 | 6802.534722 | 6782.559004 | 6778.832592 | 6771.568412 | 6771.441540 |
| 4 | 7 | 0.9 | 0.6 | 33426.578299 | 24227.602788 | 23547.269697 | 20069.020637 | 19675.583979 | 19362.002741 | 18841.820338 | ... | 20494.193166 | 20554.377651 | 20556.807509 | 20592.069985 | 20600.202449 | 20538.041432 | 20428.642319 | 20329.256952 | 20175.037066 | 20141.240174 |
| 5 | 7 | 0.9 | 0.7 | 34677.370184 | 26075.125134 | 23433.680469 | 19862.202238 | 19896.682442 | 19039.128286 | 18831.457891 | ... | 20046.193973 | 20113.558631 | 20067.368975 | 20091.244182 | 20117.912405 | 20071.883456 | 19968.212024 | 19868.072252 | 19713.281090 | 19679.029390 |
| 6 | 7 | 1.0 | 0.6 | 17818.328001 | 11228.031531 | 8340.476988 | 8545.357025 | 7532.603641 | 6290.461478 | 5751.880466 | ... | 6746.082290 | 6820.532745 | 6836.018747 | 6782.622375 | 6746.174808 | 6726.519939 | 6745.030775 | 6756.850707 | 6774.884711 | 6776.432287 |
| 7 | 7 | 1.0 | 0.7 | 16337.894141 | 10332.346436 | 7000.306648 | 7497.992465 | 7431.950940 | 5502.729419 | 5524.911924 | ... | 6482.885052 | 6533.648902 | 6532.246667 | 6513.838768 | 6498.485707 | 6497.445762 | 6483.066188 | 6481.863696 | 6480.960683 | 6479.876117 |
8 rows × 103 columns
[17]:
info_splitcv
[17]:
{'best_params_regr': {'max_depth': 6},
'best_params_ensemble': {'random_state': 0,
'n_estimators': 50,
'max_features': 1.0,
'max_samples': 0.7},
'best_n_estimators': 45,
'best_params_index': 3,
'best_score': 4033.689260470907,
'split_params': {'index_train': array([ 61, 92, 112, 2, 141, 43, 10, 60, 116, 144, 119, 108, 69,
135, 56, 80, 123, 133, 106, 146, 50, 147, 85, 30, 101, 94,
64, 89, 91, 125, 48, 13, 111, 95, 20, 15, 52, 3, 149,
98, 6, 68, 109, 96, 12, 102, 120, 104, 128, 46, 11, 110,
124, 41, 148, 1, 113, 139, 42, 4, 129, 17, 38, 5, 53,
143, 105, 0, 34, 28, 55, 75, 35, 23, 74, 31, 118, 57,
131, 65, 32, 138, 14, 122, 19, 29, 130, 49, 136, 99, 82,
79, 115, 145, 72, 77, 25, 81, 140, 142, 39, 58, 88, 70,
87, 36, 21, 9, 103, 67, 117, 47]),
'index_val': array([114, 62, 33, 107, 7, 100, 40, 86, 76, 71, 134, 51, 73,
54, 63, 37, 78, 90, 45, 16, 121, 66, 24, 8, 126, 22,
44, 97, 93, 26, 137, 84, 27, 127, 132, 59, 18, 83]),
'test_size': 0.25,
'random_state': 0}}
[18]:
res_splitcv.iloc[info_ecv['best_params_index']]['risk_test-{}'.format(info_splitcv['best_n_estimators'])]
[18]:
6498.48570671178
KFoldCV#
[19]:
from sklearn_ensemble_cv import KFoldCV
res_kfoldcv, info_kfoldcv = KFoldCV(
X_train, y_train, DecisionTreeRegressor, grid_regr, grid_ensemble,
M=50, return_df=True, X_test=X_test, Y_test=y_test,
shuffle=True, random_state=0, n_splits=5,
)
[20]:
res_kfoldcv
[20]:
| max_depth | max_features | max_samples | risk_val-1 | risk_val-2 | risk_val-3 | risk_val-4 | risk_val-5 | risk_val-6 | risk_val-7 | ... | risk_test-41 | risk_test-42 | risk_test-43 | risk_test-44 | risk_test-45 | risk_test-46 | risk_test-47 | risk_test-48 | risk_test-49 | risk_test-50 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6 | 0.9 | 0.6 | 36545.771967 | 27938.257395 | 24134.373249 | 22484.269302 | 22414.000485 | 21950.847904 | 21517.275118 | ... | 20716.631252 | 20736.461185 | 20741.668610 | 20771.880131 | 20764.847922 | 20724.517323 | 20632.514598 | 20582.426928 | 20509.866171 | 20488.539988 |
| 1 | 6 | 0.9 | 0.7 | 36177.830350 | 26909.814128 | 23494.918775 | 22117.966420 | 22352.988859 | 21574.710161 | 21334.398153 | ... | 20971.227017 | 21038.568944 | 21057.930222 | 21112.938287 | 21121.274454 | 21094.416399 | 20974.712606 | 20909.166909 | 20803.096906 | 20785.131017 |
| 2 | 6 | 1.0 | 0.6 | 18292.692037 | 12494.399173 | 10534.652350 | 9255.066365 | 9015.318876 | 8600.248786 | 8310.603633 | ... | 7488.364379 | 7465.797025 | 7438.536378 | 7406.623385 | 7395.788712 | 7369.921643 | 7363.239896 | 7343.266942 | 7323.823346 | 7306.897859 |
| 3 | 6 | 1.0 | 0.7 | 17504.625701 | 11988.718580 | 10045.440886 | 9310.529660 | 8943.994034 | 7881.303377 | 7796.536888 | ... | 7012.628902 | 7010.448402 | 7009.868242 | 6982.805845 | 6986.106436 | 6954.242473 | 6984.252017 | 6969.651320 | 6949.117880 | 6942.209406 |
| 4 | 7 | 0.9 | 0.6 | 37513.970568 | 29140.205014 | 25235.190952 | 22746.825360 | 22700.608988 | 22236.588719 | 21434.062802 | ... | 20968.167706 | 20964.003785 | 20965.059536 | 20986.504152 | 20976.639000 | 20920.110290 | 20822.718078 | 20756.068356 | 20662.774588 | 20631.524679 |
| 5 | 7 | 0.9 | 0.7 | 36535.534994 | 27236.065893 | 23964.159703 | 22014.460201 | 22375.658196 | 21824.093767 | 21351.289456 | ... | 20782.401137 | 20835.509493 | 20855.989334 | 20912.039238 | 20922.025454 | 20889.501766 | 20778.093847 | 20716.453342 | 20617.880339 | 20600.168542 |
| 6 | 7 | 1.0 | 0.6 | 18443.271257 | 12692.367011 | 10742.179078 | 9576.634688 | 9093.749373 | 8836.020076 | 8483.320394 | ... | 7589.567231 | 7566.403959 | 7537.413573 | 7499.722849 | 7483.501442 | 7445.006633 | 7439.014995 | 7414.823873 | 7390.486999 | 7370.135227 |
| 7 | 7 | 1.0 | 0.7 | 17611.199835 | 11924.784208 | 9890.939393 | 9477.430529 | 9118.334376 | 8030.870250 | 7867.956759 | ... | 7056.478013 | 7059.444686 | 7056.407264 | 7029.778004 | 7034.609903 | 6996.837311 | 7029.396458 | 7016.586506 | 6998.825844 | 6992.662602 |
8 rows × 103 columns
[21]:
info_kfoldcv
[21]:
{'best_params_regr': {'max_depth': 7},
'best_params_ensemble': {'random_state': 0,
'n_estimators': 50,
'max_features': 1.0,
'max_samples': 0.7},
'best_n_estimators': 44,
'best_params_index': 7,
'best_score': 6459.598772647386,
'val_score': array([[[35063.34458322, 35939.07984004, 36684.14739511, 33715.27011173,
41327.01790531],
[24675.57954741, 28029.25562499, 27811.81751007, 24437.13036382,
34737.50392844],
[21640.19294821, 28001.08434891, 22413.66188661, 20742.76431037,
27874.16275094],
...,
[16981.41315783, 18983.02155504, 18701.58282469, 18204.59547867,
24964.4574873 ],
[16819.75871394, 18905.14712851, 18713.80627924, 18266.68261893,
25021.57181105],
[16804.6149917 , 18920.61786553, 18700.8619768 , 18242.83754872,
25033.04059112]],
[[34440.82981543, 35056.31200754, 35505.50392758, 34808.60905139,
41077.89694803],
[24856.84534113, 26796.49263015, 25459.79869853, 25267.5821653 ,
32168.35180429],
[21970.91883632, 28632.83622643, 20011.175936 , 22904.66200669,
23955.00086764],
...,
[16469.91706412, 17942.85842715, 16928.76174278, 18536.79035297,
23559.56438967],
[16314.7960805 , 17827.03033559, 16846.70733556, 18625.29051723,
23560.8491443 ],
[16230.31923536, 17848.60512394, 16862.71966614, 18627.56571855,
23600.0783045 ]],
[[14698.7607123 , 19341.20118293, 18663.691853 , 19608.60182531,
19151.20461318],
[ 9288.57093611, 13245.04788852, 12769.69250122, 14245.29995461,
12923.3845862 ],
[ 6967.89128802, 11779.06474754, 8210.58320761, 12967.81347843,
12747.90902751],
...,
[ 3999.5843062 , 7933.3185448 , 6475.28443968, 8695.61301957,
7073.92536648],
[ 3978.92328013, 7941.30871 , 6383.15873455, 8696.82346999,
7083.61387365],
[ 3971.84034026, 7937.66491072, 6353.00940483, 8658.51429744,
7105.63634097]],
...,
[[35279.50745908, 35809.10824398, 35949.92883623, 35053.19190269,
40585.93852865],
[25669.38534688, 27949.56680589, 25460.08051813, 25648.34119935,
31452.95559431],
[23497.4919398 , 28866.55344735, 20151.61426576, 22751.33203451,
24553.80682678],
...,
[17245.0773532 , 18366.71717206, 17272.26108278, 18879.89081661,
23616.80098205],
[17063.60544168, 18292.95972297, 17223.38792004, 18922.1743427 ,
23654.24178593],
[16969.53612248, 18327.86059386, 17243.97390408, 18934.74314066,
23685.57133032]],
[[14631.53025636, 19715.86684263, 18369.05735446, 20063.44447163,
19436.457361 ],
[ 9372.79909338, 13522.47292053, 12386.12328312, 14596.47523879,
13583.96451801],
[ 7396.27619918, 11851.73272447, 8132.36053753, 12677.29413055,
13653.23180052],
...,
[ 4029.26854999, 7919.73712512, 6352.287586 , 8777.54026565,
7569.16528422],
[ 4013.72861198, 7896.63151974, 6274.04071139, 8791.90490089,
7588.76017146],
[ 4008.00139913, 7876.31008759, 6240.13676904, 8772.70606893,
7595.14144891]],
[[14546.90348333, 18131.09331047, 18628.94328335, 18461.54205193,
18287.51704787],
[ 9444.69483056, 12280.33720004, 12839.71992806, 12857.33919818,
12201.82988316],
[ 5791.37815957, 10873.95098952, 10854.18612632, 10706.06587174,
11229.11581557],
...,
[ 4126.46430885, 6665.5932463 , 6649.71318028, 7554.78217729,
7638.66922866],
[ 4147.63391126, 6667.00993029, 6670.14575688, 7607.66497255,
7682.7515881 ],
[ 4143.60272463, 6660.87045332, 6690.95061268, 7607.74483093,
7703.03270678]]]),
'test_score': array([[[39165.3323162 , 37266.99911136, 39418.30497579, 37515.62699599,
37466.07541638],
[30303.71133516, 27951.86146046, 30535.66855725, 28824.88560828,
29765.7570254 ],
[25132.58174696, 24640.22250014, 25796.87625411, 25118.50330304,
26836.21668138],
...,
[20702.89124779, 19597.02847276, 21076.24189243, 20555.68676525,
20980.28626208],
[20664.37351521, 19454.9286556 , 20979.4963262 , 20515.62458776,
20934.90777093],
[20647.01925582, 19426.8299882 , 20950.47374189, 20510.71859035,
20907.65836599]],
[[39662.2040839 , 38064.906745 , 39464.67003986, 37934.15713478,
37712.09368195],
[30890.81314418, 29301.12018517, 30621.514568 , 29017.21640016,
29394.76136548],
[27944.99800406, 26181.83960348, 27013.59560781, 24762.55218561,
25363.95540044],
...,
[20705.33509318, 20672.73504786, 21235.58724364, 20631.87760921,
21300.29955082],
[20679.58573704, 20511.09458874, 21101.5154004 , 20561.72074741,
21161.5680556 ],
[20669.64282724, 20464.19064318, 21078.18116443, 20570.65517223,
21142.98527777]],
[[18346.14510059, 17879.89409 , 19674.81513074, 18103.21744695,
20420.96515376],
[13037.31663217, 12443.45905168, 13728.15801328, 12978.34486268,
13972.02330848],
[11236.82311459, 10592.61004946, 11567.77239084, 10944.68413877,
12863.05250065],
...,
[ 7034.60443681, 7028.0415416 , 7505.14988053, 7640.19417952,
7508.34467066],
[ 7041.56157935, 7048.19283455, 7465.63284616, 7614.6578218 ,
7449.07165022],
[ 7017.70818603, 7038.95800331, 7459.92295706, 7578.08603415,
7439.8141151 ]],
...,
[[40051.18485523, 37426.36255274, 39565.72017728, 37919.82863512,
37441.51890511],
[30941.35103122, 28196.71984235, 30536.48126264, 29048.63836381,
29496.46098384],
[28284.67021057, 24954.91035021, 26559.92118039, 24187.57902697,
25485.33520472],
...,
[20733.25001227, 20060.70134276, 21148.2712261 , 20453.76720747,
21186.27691938],
[20704.72105743, 19928.59256627, 20979.32575228, 20408.90551765,
21067.85680264],
[20696.68237184, 19896.74715288, 20944.25370244, 20416.18904578,
21046.97043471]],
[[18441.05565727, 18053.14017694, 19565.86681603, 18486.53967116,
20028.1069874 ],
[12903.63637131, 12617.60682799, 13497.68418668, 13373.4350388 ,
13628.32180987],
[11449.10205102, 10618.03584122, 11492.20900414, 11342.586786 ,
12775.3466727 ],
...,
[ 6882.25526743, 7260.42696962, 7496.62272947, 7862.07617409,
7572.73822419],
[ 6880.2566495 , 7269.92848736, 7430.09224123, 7853.52588492,
7518.631732 ],
[ 6855.41795554, 7257.6635736 , 7419.19615941, 7811.33837634,
7507.06007013]],
[[18146.01266838, 17162.05374621, 18841.37500506, 17245.71676602,
18817.78862521],
[12968.57558432, 11806.3614859 , 12929.74216542, 11979.4479075 ,
12854.06854124],
[11036.70482972, 9878.84622249, 10847.20550266, 9494.79869512,
11585.03628959],
...,
[ 6814.19036431, 6715.77467929, 7228.70196355, 7145.33550997,
7178.93001472],
[ 6817.11369554, 6675.06619066, 7210.78776298, 7158.36602222,
7132.79554854],
[ 6809.05570577, 6670.97662815, 7212.36479296, 7138.75929562,
7132.15658735]]]),
'split_params': {'n_splits': 5, 'random_state': 0, 'shuffle': True}}
[22]:
res_kfoldcv.iloc[info_ecv['best_params_index']]['risk_test-{}'.format(info_kfoldcv['best_n_estimators'])]
[22]:
7029.77800406061
GCV and CGCV#
GCV estimates#
Generalized cross-validation (GCV) is a method for estimating the prediction error of an estimator. It is commonly used in the context of linear smoother, including ridge regression, lasso, and elastic net. It is a form of cross-validation without data splitting, where the estimated risk is the training error divided by the effective number of degrees of freedom of the estimator.
There are two variants of the naive GCV for ensemble learning:
‘full’: using all observations to estimate the risk
\[\tilde{R}_M^{gcv} = \frac{\|{{y}}-{{X}}\tilde{\beta}_{M}\|_2^2 / n }{(1 - \tilde{df}_M / n )^2},\]which is consistent when \(k=n\) or \(M=\infty\).
‘union’: using the union of training observations to estimate the risk
\[\tilde{R}_M^{gcv} = \frac{\|{ L}_{I_{1:M}} ({{y}}-{{X}}\tilde{\beta}_{M})\|_2^2 / |I_{1:M}| }{(1 - \tilde{df}_M / |I_{1:M}| )^2},\]which is consistent when \(k=n\) or \(M\in\{1,\infty\}\).
[23]:
from sklearn.linear_model import Ridge, Lasso, ElasticNet
from sklearn_ensemble_cv import generate_data
reset_random_seeds(0)
n_samples, n_features = 1000, 800
Sigma, beta0, X_train, y_train, X_test, y_test, _, _ = generate_data(
n_samples, n_features, coef='random', func='quad', sigma_quad=.1,
rho_ar1=0., sigma=.5, df=np.inf, n_test=1000,
)
kwargs_regr = {'alpha': 0.01*X_train.shape[0], 'fit_intercept':False}
kwargs_ensemble = {'max_samples': 0.5, 'bootstrap':False}
regr = Ensemble(estimator=Ridge(**kwargs_regr), n_estimators=100, **kwargs_ensemble)
regr = regr.fit(X_train, y_train)
[24]:
df_gcv = regr.compute_gcv_estimate(X_train, y_train, M0=25, type='union', return_df=True)
[25]:
df_risk = regr.compute_risk(X_test, y_test, return_df=True)
CGCV estimates#
The correct GCV estimators are shown to be consistent for arbitrary ensemble sizes:
There are two options of the risk component estimators:
\(\#=\)’full’: using full observations to estimate \(R_{m,m}\).
\(\#=\)’ovlp’: using overlapping observations to estimate \(R_{m,m}\).
Intuitively, the former should be more robust as more observations are used.
[26]:
df_cgcv = regr.compute_cgcv_estimate(X_train, y_train, M0 = 25, type='full', return_df=True)
[27]:
plt.plot(df_gcv['M'], df_gcv['estimate'], label='GCV estimate')
plt.plot(df_cgcv['M'], df_cgcv['estimate'], label='CGCV estimate')
plt.plot(df_risk['M'], df_risk['risk'], label='risk')
plt.legend()
plt.show()
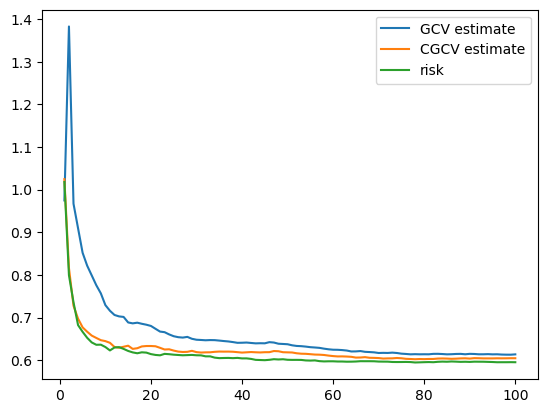
GCV and CGCV for tuning#
Below we apply CGCV for tuning ensemble parameters for ridge. The function GCV also supports naive GCV estimates (when corrected=False), though they are inconsistent to prediction risk and are only included for completeness. Therefore, we do not recommend to use naive GCV for tuning.
Both GCV and CGCV are proposed for subagging (when bootstrap=False in kwargs_regr), however, they also provide reasonable estimates for bagging numerically, as we illustrate below.
[28]:
from sklearn_ensemble_cv import GCV
grid_regr = {'alpha': np.array([0.01,0.05])*X_train.shape[0]}
grid_ensemble = {'max_samples': [0.6,0.8]}
res_cgcv, info_cgcv = GCV(
X_train, y_train, Ridge, grid_regr, grid_ensemble,
M=100, M0=25, corrected=True, type='full', return_df=True, X_test=X_test, Y_test=y_test,
)
[29]:
res_cgcv
[29]:
| alpha | max_samples | risk_val-1 | risk_val-2 | risk_val-3 | risk_val-4 | risk_val-5 | risk_val-6 | risk_val-7 | risk_val-8 | ... | risk_test-91 | risk_test-92 | risk_test-93 | risk_test-94 | risk_test-95 | risk_test-96 | risk_test-97 | risk_test-98 | risk_test-99 | risk_test-100 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 10.0 | 0.6 | 1.270438 | 0.942270 | 0.825168 | 0.763242 | 0.731527 | 0.708762 | 0.693972 | 0.688929 | ... | 0.632743 | 0.632524 | 0.632333 | 0.632490 | 0.632899 | 0.633189 | 0.633581 | 0.633870 | 0.634254 | 0.634421 |
| 1 | 10.0 | 0.8 | 1.689871 | 1.135225 | 0.944082 | 0.853987 | 0.792728 | 0.749514 | 0.716791 | 0.705366 | ... | 0.572260 | 0.572334 | 0.572093 | 0.571998 | 0.572339 | 0.572438 | 0.572891 | 0.573057 | 0.573264 | 0.573372 |
| 2 | 50.0 | 0.6 | 1.134798 | 0.886978 | 0.791813 | 0.744230 | 0.720062 | 0.706429 | 0.693548 | 0.691763 | ... | 0.659251 | 0.659057 | 0.658901 | 0.659089 | 0.659451 | 0.659735 | 0.660065 | 0.660349 | 0.660731 | 0.660897 |
| 3 | 50.0 | 0.8 | 1.296153 | 0.943016 | 0.811787 | 0.753779 | 0.714835 | 0.690649 | 0.670342 | 0.666039 | ... | 0.593066 | 0.593141 | 0.592986 | 0.592990 | 0.593272 | 0.593415 | 0.593756 | 0.593978 | 0.594269 | 0.594402 |
4 rows × 203 columns
[30]:
info_cgcv
[30]:
{'best_params_regr': {'alpha': 10.0},
'best_params_ensemble': {'random_state': 0,
'n_estimators': 100,
'max_samples': 0.8},
'best_n_estimators': 100,
'best_params_index': 1,
'best_score': 0.583519102039084}
[31]:
res_cgcv.iloc[info_cgcv['best_params_index']]['risk_test-{}'.format(info_cgcv['best_n_estimators'])]
[31]:
0.5733721598232984